
What is Web Scraping?
Web scraping is an automated method used to extract large amounts of data from websites. the data on the websites are unstructured. web scraping helps to collect these unstructured data and store it in a structured form. there are different ways to scrape websites such as online
services, APIs or writing your own code. Data displayed by websites can only be viewed using a
web browser. most websites do not allow you to save a copy of this data to a storage location or database. if you need the data, the only option is to manually copy and paste the data – a very tedious job which can take many hours or days to complete. Web scraping is the technique of automating this process, so that instead of manually copying the data from websites, the web scraping software will perform the same task within a fraction of the time .
How Web Scrapers Work?
Web Scrapers can extract all the data on particular sites or the specific data that a user wants. Ideally, it’s best if you specify the data you want so that the web scraper only extracts that data quickly. For example, you might want to scrape an Amazon page for the types of juicers available, but you might only want the data about the models of different juicers and not the customer reviews. so when a web scraper needs to scrape a site, first it is provided the URL of the required sites. Then it loads all the HTML code for those sites and a more advanced scraper might even extract all the CSS and JavaScript elements as well. then the scraper obtains the required data from this HTML code and outputs this data in the format specified by the
user. Mostly, this is in the form of an Excel spreadsheet or a CSV file but the data can also be saved in other formats such as a JSON file.
Python and Web Scraping
Python seems to be in fashion these days! It is the most popular language for web scraping as it can handle most of the processes easily. It also has a variety of libraries that were created specifically for Web Scraping. Scrapy is a very popular open-source web crawling framework that is written in Python. It is ideal for web scraping as well as extracting data using APIs.
Beautiful soup is another Python library that is highly suitable for Web Scraping. It creates a parse tree that can be used to extract data from HTML on a website. Beautiful soup also has multiple features for navigation, searching, and modifying these parse trees.
Selenium is an automation testing framework for web applications, websites which can also control the browser to navigate the website just like a human. Selenium uses a web-driver package that can take control of the browser and mimic user-oriented actions to trigger desired events.
Web Scraping with Beautiful Soup
Flipkart is a one of the biggest E-commerce website with lot of data, so let’s scrape some using Python! this is a basic simple example. in this example we’re going to be use BeautifulSoup.
Importing necessary libraries
from bs4 import BeautifulSoup import requests import csv import pandas as pd
Find URL that we want to extract
Inspect the page and find elements
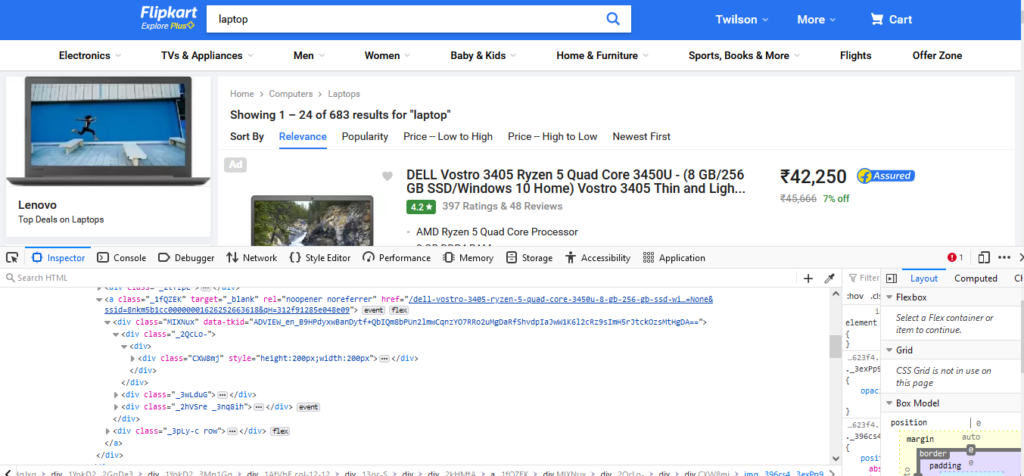
code for scraping
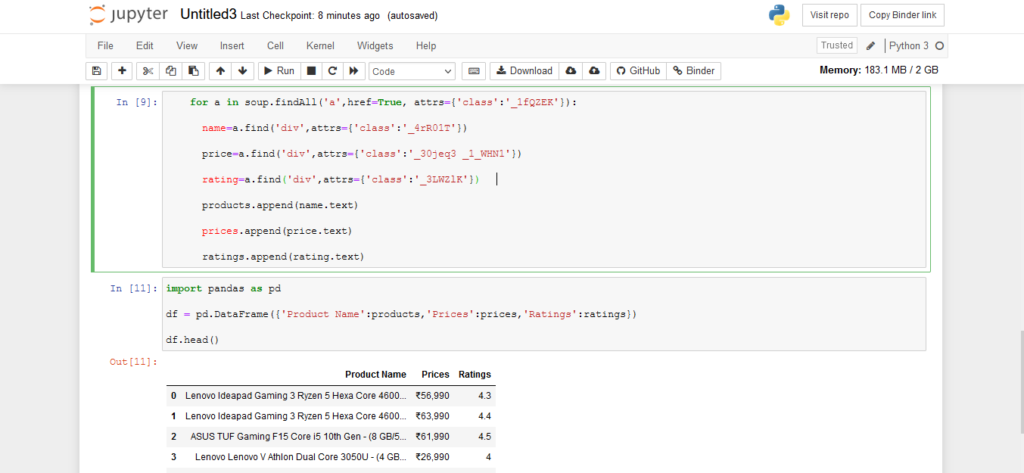
for a in soup.findAll('a',href=True, attrs={'class':'_1fQZEK'}):
name=a.find('div',attrs={'class':'_4rR01T'})
price=a.find('div',attrs={'class':'_30jeq3 _1_WHN1'})
rating=a.find('div',attrs={'class':'_3LWZlK'})products.append(name.text)
prices.append(price.text)
ratings.append(rating.text)
Store the result in desired format
df = pd.DataFrame({'Product
Name':products,'Prices':prices,'Ratings':ratings})
df.head()
Web Scraping with Selenium
Instagram is a very massive social media platform with tons of data, so let’s scrape some using Python! this is a basic simple example. Python has several different web scraping packages,
beautiful soup and selenium are a few, in this example we’re going to be using Selenium
let’s go open up an Instagram page, I used ehackifytrainings account below
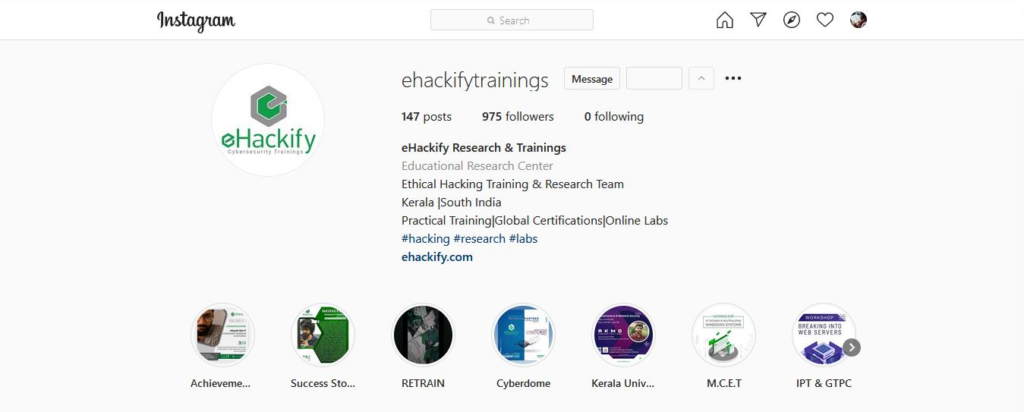
As you can see, there are a few data points we can scrape, things like number of posts, followers and following as well.
Importing necessary libraries
import selenium from selenium import webdriver import pandas as pd from webdriver_manager.chrome import ChromeDriverManager
we want to install and declare our driver and point it to a website
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://www.instagram.com/ehackifytrainings/)
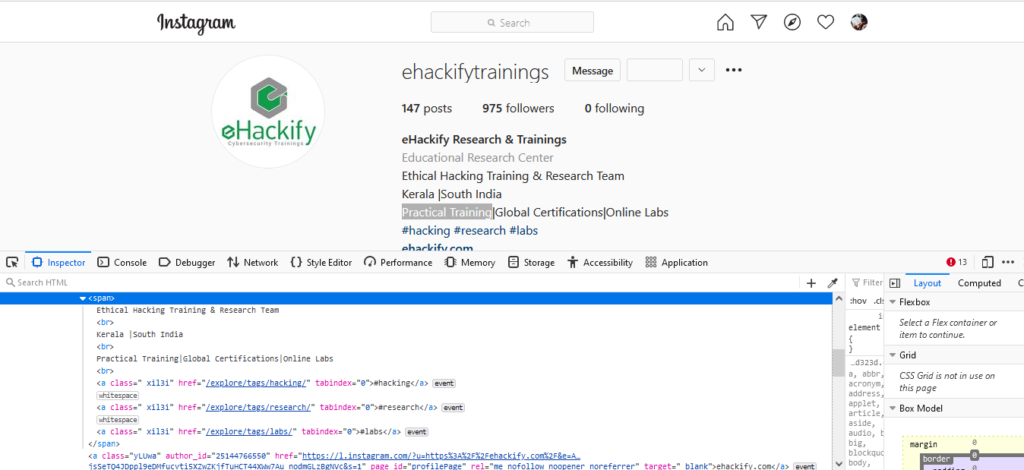
declare 3 variables for Posts,followers and following, this will hold the text of those values from the website.
Posts = driver.find_element_by_xpath('PUT FULL XPATH HERE').text
Followers = driver.find_element_by_xpath('PUT FULL XPATH HERE').text
Following = driver.find_element_by_xpath('PUT FULL XPATH HERE').text
code for scraping
import selenium
from selenium import webdriver
import pandas as pd
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get(' https://www.instagram.com/ehackifytrainings/')
Posts=driver.find_element_by_xpath('/html/body/div[1]/section/
main/div/ul/li[1]/a/span').text
Followers=driver.find_element_by_xpath('/html/body/div[1]/section/main/div/ul/li[2]/a/span').text
Following=driver.find_element_by_xpath('/html/body/div[1]/section/main/div/ul/li[3]/a/span').text
print(Posts)
print(Followers)
print(Following)
data1 = {'Posts':[], 'Followers':[], 'Following':[],}
fulldf = pd.DataFrame(data1)
row = [Posts, Followers, Following]
fulldf.loc[len(fulldf)] = row